

If you were asked to integrate a TTS voice into a high-stakes project just five years ago, you’d likely said no. Why would you integrate a robotic, monotone and unconvincing voice that was, quite simply, a technical and creative liability?
Well, newsflash! That liability has been flipped into a critical business asset you now need to know about. We’re going past the global text-to-speech market size to analyze the core text-to-speech market trends that separate the serious players from all the noise. We will show you how to vet a partner who will be an uncompromising co-creator and ethical ally.
Key Takeaways
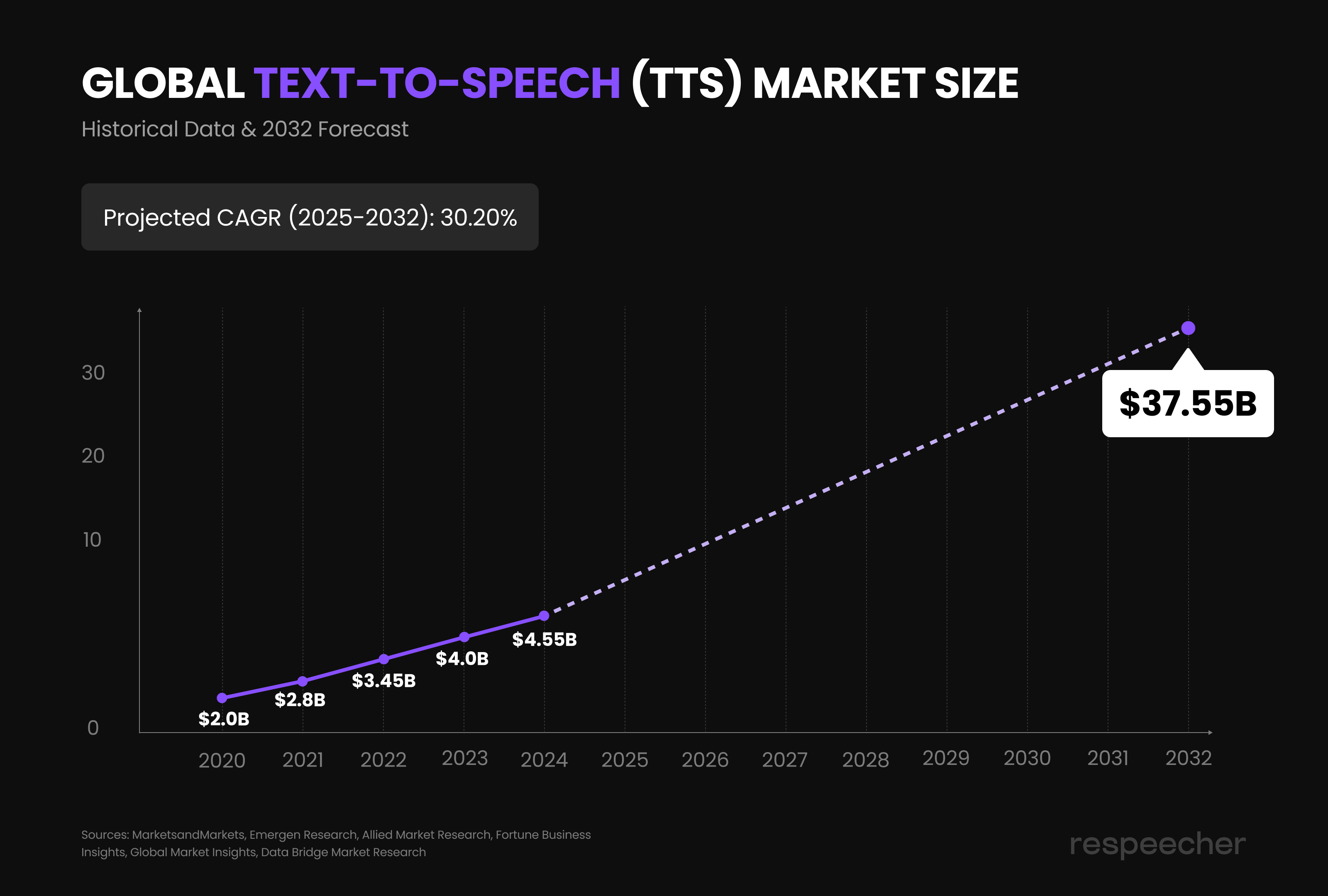
- The TTS glow-up is very real. Neural AI has delivered the fidelity we've been waiting for. The market is surely coming for a $37 billion by 2032, flipping TTS into a critical business asset.
- You must demand the Trifecta. High-stakes media requires quality, speed, and integrity. That means expecting hyper-expressive voices, sub-300ms latency (no lag), and ironclad ethical contracts that protect the voice performer's rights.
- It's a workflow accelerator. High-fidelity TTS is an immediate value generator for film, gaming, and marketing teams. It allows for agile prototyping (the fastest "table read" available), powers dynamic character dialogue, and creates flawless AI voice agents and chatbots that maintain a consistent brand identity 24/7.
Global Text-to-Speech Market Growth: The Impact of Neural AI
For the longest time, TTS was a great idea with one single flaw: it sounded awful. Its output was either too stiff, or too robotic: it gave unusable audio, and therefore, was widely rejected.
But AI has finally delivered the fidelity we've been waiting for and caused the fundamental shift — by actually making the technology viable.
That single change has turned TTS from a long-time gimmick into a cornerstone of media and, naturally, unlocked massive investment, driving the global Text-to-Speech market from $4.55 billion in 2024 toward a projected $37.55 billion by 2032.
The Technical Leap: Why "Neural" Matters
Neural Text-to-Speech (NTTS) is built on Deep Neural Networks (DNNs), advanced AI systems that learn vocal patterns directly from massive datasets.
The DNNs learn all the subtle nuances of human performance called prosody (natural stress, rhythm, and emotion in human speech). The synthetic voice can now deliver the expressive quality required for professional storytelling we’ve longed for decades.
That’s not a niche tool anymore, and frankly, we don't have to guess where the industry is heading:
- The market's overall explosive growth is forecast at a 30.20% CAGR through 2032, with a clear demand for hyper-realistic voices.
- The specialized AI Voice Generators segment—which tracks high-fidelity neural solutions—is growing with its CAGR estimated as high as 32.51%.
- This focus on quality means the Neural and Custom voice types already capture over 83% of the total TTS voice type market share.
When filmmakers and brand teams invest in TTS, they are investing here. With this massive focus on high-fidelity performance, solutions that require instant, natural, and expressive dialogue are now commercially viable at scale.
Top Text-to-Speech Market Trends for Creative Industries
High-stakes audio demands excellence, and the current text-to-speech market size confirms that AI has finally met the brief. Our work is now defined by three non-negotiable mandates (Quality, Speed, and Integrity) that elevate AI to a truly sophisticated co-creator.
Hyper-Expressive Voice Synthesis
The era of merely clear TTS is over. Today, the core technical goal is emotional realism. A voice doesn’t just read a line, but rather performs it:
- Creative necessity: In animated features or dialogue-heavy games, the synthetic voice must convey character nuances, anger, or laughter. High-quality neural voices create dynamic real-time narratives that adapt instantly based on user choice and eliminate the cost and inflexibility of pre-recorded dialogue.
- Quantified quality: The industry uses the Mean-Opinion Score (MOS) to measure quality, where a human voice typically scores 4.5–4.8. Advanced neural models are now achieving MOS scores as high as 5.53, setting a completely new benchmark and proving the synthesis quality has exceeded the traditional scale's limits.
Low Latency API
For successful human-computer conversation, long delays break the natural back-and-forth rhythm. The metric we track here is Time-to-First-Audio (TTFA), which measures the delay before the listener hears the relevant audio response.
The industry benchmark for fluid conversation often targets responses that initiate in the sub-300 ms range. But that’s a bare minimum: advanced streaming TTS systems are already pushing well under 200 ms.
Ethical Voice Governance
As technology gets frighteningly good (and can replicate a voice from a 15-second sample), the industry must shift from passive concern to proactive protection.
For AI to truly become an ally, it must operate on a foundation of trust — respecting the performer's rights as a digital asset owner. Groups like SAG-AFTRA are setting the tone for the entire industry with four core pillars of ethical AI use:
- Transparency: The right to know the intended use of the likeness.
- Consent: The right to grant or deny permission for model use.
- Compensation: The right to fair pay for the digital voice asset.
- Control: The right to set limits on how, when, and where the digital asset is used.
Opportunities for Businesses: The Practical Toolkit
The high-stakes media market demands two things: absolute quality and radical efficiency. And the new generation of Neural TTS becomes a specialized production asset designed to deliver both.
Here’s where high-fidelity TTS immediately generates measurable value for your team:
Filmmaking & Pre-Production
Any time spent on logistical audio is time wasted on creative direction. High-quality Text-to-Speech and its real-time API capabilities simplify two core challenges:
- Agile prototyping & temp VO: You can write a script into the system and immediately generate a high-quality voice track for animatics or early-stage dialogue testing. You’ll identify pacing issues and awkward lines before a single actor enters the booth — consider this the fastest and most effective table read ever available.
Gaming & Interactive Media
If you want an endless replayability, you have to solve the liability of static, pre-recorded audio. A TTS API lets you build a living world that reacts to the player and not plays the same static audio files over and over.
- Dynamic dialogue: Instead of storing massive audio files for thousands of static lines for Non-Player Characters (NPCs), the API allows for non-repeated dialogue. It instantly generates context-aware responses, providing true depth and infinite replayability.
Conversational AI & Customer Experience (CX)
This is the exact part where the TTS API stops reading a script and starts having a real conversation.
- High-fidelity voice agents: They provide personalized, 24/7 support while guaranteeing your brand voice remains perfectly consistent. A fair game: you handle the complex exceptions; the AI handles the volume.
Global Marketing & Brand Scaling
Your brand's voice is how your audience recognizes you among others. Text-to-Speech is the key to scaling that asset globally without sacrificing any ounce of quality.
- A/B testing & multilingual voiceovers: Need to test a more casual brand persona in the French market, or a formal one in Japanese? With TTS, that’s no problem. Generate high-quality multilingual drafts and use A/B testing to instantly verify that the tone resonates properly with each regional target demographic.
How to Choose a High-Fidelity TTS Solution
The market is full of options, but the choice is simple: you have to secure a long-term production partner that is as committed to your legal safety and final output quality as you are.
1. Never Compromise on Human-Parity Audio
A low-fidelity voice is a threat to brand trust. Full stop. The technological leap to Neural TTS means there is no longer any excuse for a generic voice ever.
Make sure your provider is committed to delivering true human-parity audio. They must prove their models consistently handle complex prosody, tone, inflection, and all the other nuances that make a performance believable.
Remember this simple truth: anything less than the highest possible fidelity is a direct risk to your brand.
2. Professionalism, Regardless of Client Size
We decline projects that demand average quality. Whether it's for the biggest Hollywood company or a niche content creator, your business deserves a provider that operates with exceptional perfectionism.
You have a reputation to protect, and that means your vendor must share your 'final cut' mentality. Your partner needs to guarantee the highest possible quality delivered on deadline to demonstrate genuine respect for your production pipeline and creative vision.
3. Clear Contracts and Consent
Many companies are releasing technology without managing the rights of the likeness or moderating content. You ignore them at all costs.
Your partner must adhere to a strict ethical framework that secures your digital assets:
- Demand clear and explicit contracts for voice likeness and model use — the voice artist must be a willing partner.
- Ensure the voice models are trained on ethically sourced cleared data. If a provider can't trace the origin of their training data, they're not a professional partner.
In this industry, choosing the unauthorized but cheap path will cost you the business trust you are working hard to build.
Top Ethical TTS Providers for Media and Enterprise
You shouldn’t have to guess which TTS partner is actually serious. We’ve curated a look at three leaders whose platforms back up their good game with technical focus and rock-solid governance.
#1. Respeecher
We are a team of voice enthusiasts focused on one mission: enabling unparalleled creative efficiency for media professionals.
- The <200ms performance guarantee. When you need instant audio for core functions, you rely on our technical leadership. Our Real-Time TTS API is engineered for ultra-low latency, initiating audio streaming in milliseconds. This is what makes voice agents seamless and viable — send text, get a voice stream back.
- Integrity-first rights management: Our ethical policy is our product. Every voice in our system is 100% legal, sourced with mandatory written consent, and backed by a transparent revenue-sharing model for the actor.
In creative work, you know the truth is in the delivery, and you cannot lose that. Our Speech-to-Speech (STS) technology is our vow: we preserve the actor's raw, emotional performance and deliver the highest expressive quality, every single time.
This is the work we pour our absolute pride into, perfected across large-scale projects. We’re here when performance is non-negotiable.
#2. WellSaid Labs
WellSaid Labs excels at optimizing the content pipeline for raw acoustic quality. They are built for studio readiness – the ideal choice for high-volume content in primarily English markets.
WellSaid has mastered the balance between quality and speed: they deliver output fidelity up to 96 kHz — the critical standard for high-end audio production. This quality allows for deep post-production mastering, and their speed (G2 rating of 9.2 for Speed of Generation) ensures unmatched throughput velocity.
The company maintains a powerful ethical defense — a proprietary data ecosystem. WellSaid relies strictly on private, legally vetted datasets from contracted voice talent.
#3. Murf AI
Murf AI is the vendor for zero-risk tolerance. They hold some of the most rigorous certifications in the market, including SOC 2 Type II and ISO 42001, which is the only language highly regulated industries truly trust.
You need to protect your IP, and Murf knows it. Their Enterprise policy guarantees 'No Training on your Data,' which immediately kills the risk of any leakage. Pair that security with their offering of over 30 languages: they deliver the most secure and scalable solution available for geographically dispersed teams.
Final Thoughts
The market has settled the score: good riddance to the robotic voice! The new technology now gives you unparalleled creative efficiency, but you must demand the trifecta in return: highest possible expression, zero-latency performance, and an ironclad ethical backbone.
That’s the price of entry for high-stakes media. You’re choosing your co-creator, so choose one who fully shares your integrity.



.png?width=477&height=264&name=How%20Much%20Does%20ADR%20Cost%20(1).png)
